

贝叶斯统计与贝叶斯公式
逻辑推理的一个常见误区是以偏概全。一个典型例子是:许多渠道显示,地震发生时伴随的一个常见现象是动物园里的动物普遍地焦躁不安。于是,有些人就把动物焦躁不安作为地震预测的一个强有力的手段。更有甚者,一旦发现动物普遍地焦躁不安,直接就说,哪里要发生地震了。那,这样的推理具有什么样的缺陷呢?
地震和动物焦躁不安都是不确定性事件。用A表示动物园里的动物普遍地焦躁不安,用B表示地震的发生。那们上述推理犯了这样一个错误:
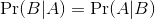
更加直白一点讲,误将正命题的正确性当成了逆命题的正确性。
仔细想想,我们在日常生活当中,实际上经常性地犯这样类似的错误。比如,在一次列车旅行当中,坐在你对面的旅客和你攀谈。你注意到这位朋友中等身材。简短的语言交流之后,你发现他思维敏捷程度甚至不输任何人。继续接触下来,你感觉这个人做的工作似乎与应急管理非常类似。继续聊天,那人告诉你他比王宝强还喜欢K歌。这个时候你边上的另一位旅客说,你猜猜他是做什么工作的?给两个选项:
(A)应急管理研究
(B)农民
你会选哪个呢?如果你选(A),但你就陷入了刚刚讲的推理误区了。对照贝叶斯公式,你发现你漏掉了什么?
你在这个推理过程当中漏掉了背景信息!在一个这样的列车上,你说是研究员多呢,还是农民多?反过来,如果坐的是高铁,那你直接猜他做应急管理研究。
上面讲的这个推理误区,在认知心理学里称作为Representative Bias.
贝叶斯统计是上述贝叶斯公式的一个简单推广。这个推广,简单地讲,无非是做了下面的一点置换:
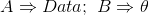
进一步,按统计学的习惯写法,将
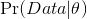
记作
, 也就是在给定数据下的似然函数,那么贝叶斯统计的参数估计的公式就表现为

上式中三项分别为后验分布、似然函数、先验分布。
理解上述贝叶斯统计公式,有几个需要注意的问题。
第一,这是中国人的智慧,永远不要把话讲得太满。什么意思呢,我们不要将先验概率的定义域限得太死。没有充分的、机理上的证据,不要将定义域的上下限定得过于具体。比如,实际计算时一个常见的错误是人为地定一个位于某个确定区间内的均匀分布,然后还宣扬自己没有先验信息。这样做的直接后果是,将一大批可能的黑天鹅[注1]都赶尽杀绝。引申开来就是,自己的推理永远跳不出你先验分布的框框里面。要注意,如果在某个区间
,那么无论数据(事实)如何,在该区间
永远是零——这就是屁股决定脑袋的贝叶斯。
第二,如果将先验分布理解为对不确定性参数所有先验知识和信息的一个概率描述,那么,贝叶斯更新表现为似然函数乘以先验分布,就可以更加直观地理解为它是不同渠道信息的一个融合。这与数据本身不同观察值在条件相互独立前提下构造似然函数的办法是一脉相承的。这里的关键问题在于,如何对先验信息和知识进行概率化表达?
第三,从预测的角度,贝叶斯学派和传统的Fisher学派也是一脉相承的。假设某个随机量
服从某个参数化概率模型,记作
那么,在给定数据下的预测值可以写成如下形式:
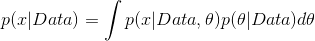
引入条件独立性[注2],式中第一项
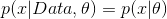
即为随机变量的固有不确定性模型,而第二项
在贝叶斯统计当中即为参数的后验分布,在Fisher学派里头即为似然函数。第二项反映的是模型参数的不确定性。这样,这个预测公式既包含了固有不确定性(Aleatory uncertainty),又包括了认知的不确定性(Epistemic uncertainty)。
第四,贝叶斯统计往往涉及到高维积分,这一点从上面的预测公式容易看出。当模型参数比较多,后验分布经过似然函数的藕合后通常变是相互关联。因此在计算许多统计量如后验均值、方差时,都将涉及到高维积分。为此,许多现代统计计算方法如Markov-chain Monte Carlo, Quasi Monte Carlo等应用而生。

